 por
por No trabajo directamente con Gitlab sino con otro proveedor para mis repositorios de código de la empresa y otros clientes pero menuda sacudida se llevaron los que si tienen almacenada su informacion ahi pues desde hace aproximadamente 12 horas el servicio GitLab.com esta fuera de linea por culpa de lo que podriamos considerar un error humano. En 2014 este proveedor de almacenamiento en la nube para códigos fuente y administrador de proyectos obtuvo una ronda de financiación cercana a los $20 millones de dólares los cuales seguramente estarán más que preocupados con estos hechos pues podrían tirar el costo de sus acciones e inversiones para el siguiente trimestre.
Durante la tarde (hora del pacífico) de ayer la startup estuvo actualizando mediante Twitter acerca de la causa de estos mantenimientos, que dicho sea, fueron causados por un agente externo según cuenta su handler en Twitter: High load was partially caused by 47 000 IPs logging in to the same account at a high rate. Este tipo de ataque es similar a lo ya conocido como «Ataque para acceso por fuerza bruta» y causó que tuvieran que hacer algunas reconfiguraciones en sus bases de datos para mitigar este intento de intrusión.
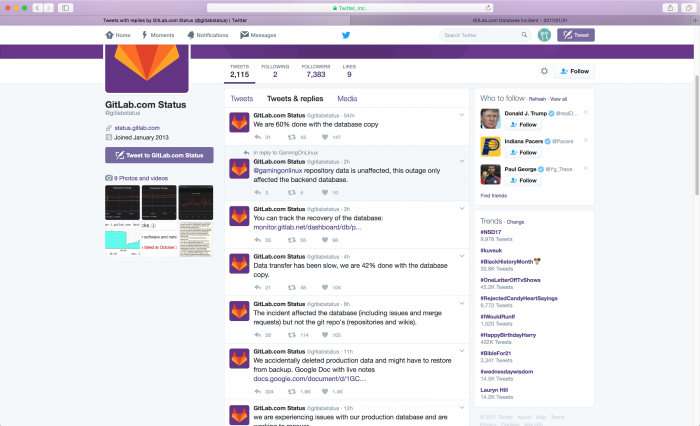
Posterior a hacer esa reconfiguración siguieron teniendo problemas y, suponemos, por ahí de las 3:28 PM del Martes 31 de Enero fue que el cansado operador de sistemas de Gitlab por error borro un directorio conteniendo cerca de 300GB de información enviando a todos los usuarios de la plataforma fuera de servicio y sin acceso a sus códigos. Lo mas complicado de creer es que una startup con tal valoración por inversionistas no tuviera sus sistemas de respaldo probados y al dia pues según rescata The Register los procesos de respaldo son scripts manuales en Bash que corren aleatoriamente. El infame comando ejecutado por el operador de sistemas no fue otro sino rm -rf que ejecutado con la cuenta adecuada borra sin preguntar al usuario y de manera recursiva todo lo que se encuentre.
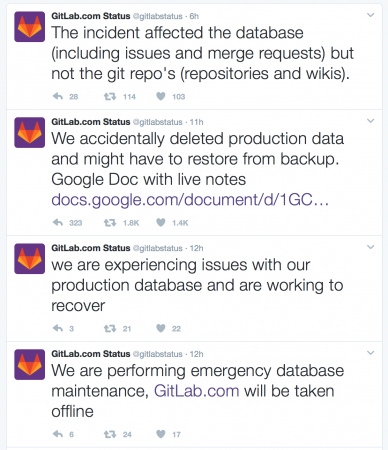
Ahora mismo están haciendo un live streaming con el proceso de restauración a fin de calmar a los developers y sus inversionistas, supongo, pero es de preocuparse que el mas viejo respaldo data de hace 6 horas para una plataforma en producción. Dicho sea de paso no se han perdido información de codigo de clientes sino codigo del backend que permite a los clientes acceder a su información almacenada en los servidores de la empresa que cabe mencionar hace algún tiempo optaron por utilizar su propio centro de datos y servidores para crecer a un paso más acelerado pero Connor Shea ha dicho que estarán trabajando en mejorar su infraestructura de respaldos así como investigando mover sus servidores a la nube.
Al momento de escribir esta nota, 7am EST, llevan mas del 60% del respaldo recuperado por lo que en el transcurso del dia deberian estar de nuevo en línea. De cualquier manera no esta de mas recordar a nuestros amigos de Enterprise de revisar periódicamente sus sistemas de respaldo y ejecutar tareas de emergencia de manera controlada para saber cómo actuar en caso de una eventualidad.
Fuente: The Register y Gitlab en Twitter