 por
por

En un proyecto que están llevando a cabo un grupo de investigadores en el Instituto Allen de Inteligencia Artificial de la Universidad de Washington, llamado LEVAN (Learn EVerything about ANything), desarrollaron un nuevo algoritmo que solo puede aprender de todo sobre cualquier cosas.
Este algoritmo, de acuerdo a uno de los investigadores Carlos Guestrin, no está supervisado por humanos, pero si está «supervisado por la Web». LEVAN utiliza la web para aprender todos los conceptos que necesita conocer y lo hace solo a través de texto e imágenes.
Lo interesante es que este algoritmo no necesita de un gran poder de computación, como otros modelos de Inteligencia Artificial necesitan, especialmente en la etapa de entrenamiento. LEVAN fue diseñada para poder trabajar sin problemas en la nube de Amazon.
Este algoritmo rastrea Google Books Ngrams para aprender frases comunes asociadas a un concepto, así comienza a buscar por esas frases en imágenes en la web y de esa manera aprende como es cada cosa.
Algo interesante también es que aprende cuando distintas palabras o frases, significan lo mismo y también lo hace con imágenes, ya que luego de analizar las que crea suficientes, puede determinar que es la misma persona la que se encuentra en las mismas.
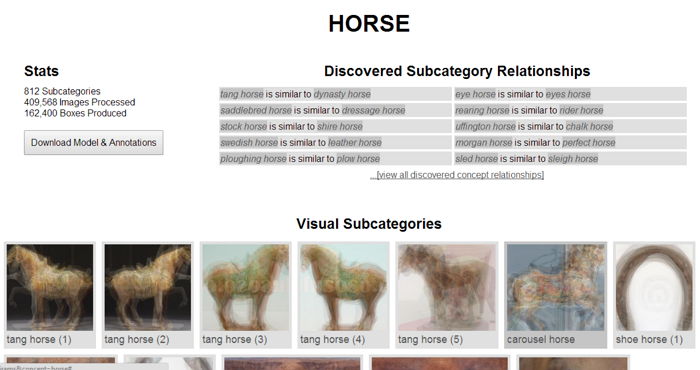
Hasta ahora este algoritmo ha modelado 153 conceptos diferentes, más de 60.000 sub-categorías y anotó información sobre que incluyen y que está sucediendo en más de 40 millones de imágenes.
Si quieren en el sitio del proyecto pueden ver los resultados de cada uno de los conceptos examinados por este algoritmo y hasta pueden descargar los modelos y anotaciones. Según indican en el sitio, LEVAN es como una enciclopedia para el visitante. Además si quieren que investigue sobre un concepto en particular lo pueden pedir a través de un formulario que tienen en el sitio web de LEVAN, en el que deben de ingresar el concepto, que quieren que investigue y su email para que cuando termine, los notifiquen.
Enlace | LEVAN